Background
The team had built a sophisticated probabilistic cyber-risk analysis engine — strong on accuracy, but accessible only to people who could author specifications by hand. The engine’s input format is meant for domain experts; the target users — insurance underwriters and SME operators — couldn’t engage with it directly.
The platform’s job was to bridge that gap: turn the engine into a product that non-experts can actually use, with a guided experience that takes around ten minutes instead of needing a specialist to author specs from scratch.
What it does
At the highest level, the platform takes a single company website URL and walks the user through:
- Automated pre-fill — the platform tries to do as much as possible automatically from public information.
- Verification — the user confirms or corrects the pre-filled values, with a confidence cue showing where to focus attention.
- Conversational gap-filling — for fields that can’t be inferred from a website, an AI assistant collects them in natural-language groups rather than as a flat 22-question form.
- Structured form review — a multi-step intake wizard pre-filled from the previous steps, with draft auto-save.
- Loss estimation — a financial-impact estimate grounded in historical incident data, with reasoning the underwriter can audit.
- Risk analysis report — executive summary, system health overview, and prioritised recommendations.
The design goal: an underwriter sees a usable risk profile within ten minutes of entering a URL, and never loses progress on a refresh or a tab close.
Architecture at a glance
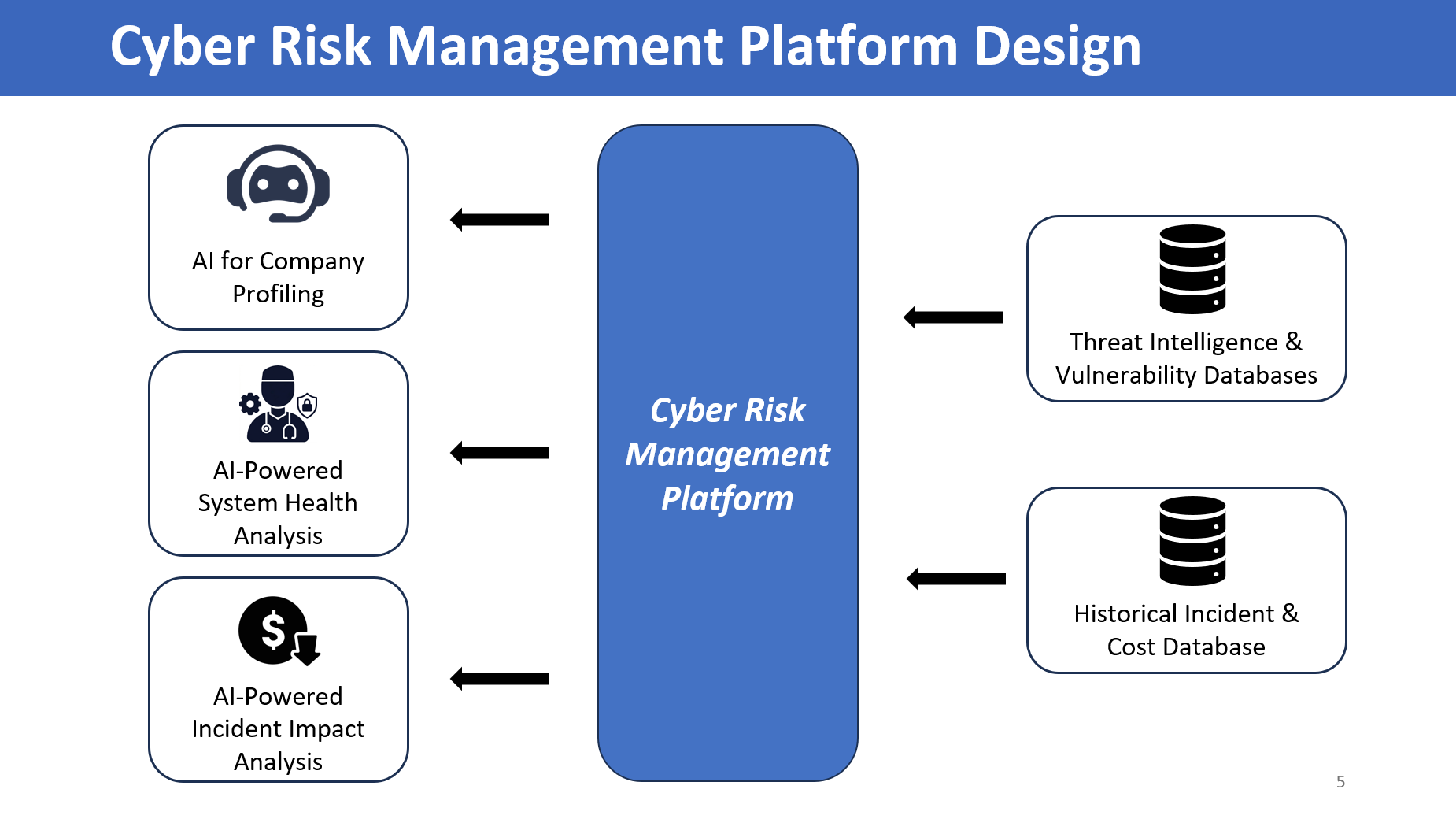
A one-glance view of how the parts fit together. The platform sits in the middle; the two databases on the right are its evidence sources (live threat-intelligence + vulnerability feeds, and a historical incident-cost database), and the three AI capabilities on the left are what the user actually interacts with — company profiling from a URL, system-health analysis on the collected profile, and incident-impact (loss) estimation grounded in historical incidents. Everything I describe below — the intake wizard, the AI assessment bot, the RAG loss estimation, the JELAS risk engine — slots into one of these five boxes.
My role — main in-team developer (product side)
The risk engine itself is a separate research artifact built by the team. My work focused on turning it into a deployable product. I owned the end-to-end product layer below.
Frontend
- Multi-page web frontend with a consistent dark-cyber design system across the eight user-facing pages — glassmorphism cards, gradient buttons, unified back-navigation, accessible colour contrast.
- Five-step guided intake wizard with step navigation, client-side validation, JSON import / export, and draft auto-save — so a partial submission survives a refresh, a tab close, or a return-tomorrow workflow.
- Conversational AI bot UI with streaming responses and a real-time Collected Fields side panel that updates as the user replies, so the user can see exactly what the platform is learning about them.
- Confidence-coded form fields (high / medium / low badges) on the verification page so users scan rather than re-read every value.
- Result pages for loss estimation and the final risk report, with executive summary, structured tables, and prioritised recommendations.
Backend
- Flask application with the full route layer covering intake, draft persistence, AI streaming, analysis triggers, and result retrieval.
- Server-Sent Events (SSE) for streaming AI responses and progress on long-running analysis jobs, so the UI never blocks on a slow upstream call.
- Per-company submission storage with a
latest + historyretention pattern that makes resubmissions safe and auditable. - Integration glue between the user-facing flow and the team’s underlying risk engine — keeping the engine itself untouched while letting the product control framing, error handling, and progress reporting.
Database & data layer
- SQLite-backed user / session / approval tables, auto-created on first run for zero-config bootstrap.
- Versioned per-company submissions with draft and publish states.
- Structured logging for audit trails and AI request tracing — important for a domain where decisions need to be explainable after the fact.
Authentication & user management
- Google OAuth sign-in via Authlib, with the email / password fallback wired but hidden by default.
- Admin-gated approval workflow — new users land on a pending-approval screen until an admin promotes them; SMTP notifications fire on registration, approval, and password reset.
- Two user roles (SWE self-assessment / insurance underwriting) with role-driven page routing — same pages, different next-step links, so each persona sees the most relevant flow without seeing irrelevant steps.
- Admin panel for user approval, role assignment, and account management; a Flask
before_requesthook enforces auth + approval on every gated route.
Cloud deployment & ops
- Production deployment on a shared Linux server, with
gunicornas the WSGI process supervisor — daemonised with PID file management, rotating logs, and graceful shutdown. - Public access via a reserved HTTPS tunnel so the demo URL stays stable across sessions — early reviews flagged URL churn as the single most common pain point, so this was a small but meaningful UX investment.
- Health-check + log-tail commands wired into the run scripts so on-call status can be verified in under thirty seconds.
Internal tools, feedback, and admin
- Admin user management UI (approve / reject / role change / disable) with audit logging.
- Feedback collection with persistence — users can submit comments from inside the platform, the team reviews and triages from an admin view, and feedback is tied back to the user’s session for context.
- Draft & publish split for company submissions — drafts are private to the user, published submissions become available to the team for review.
Tech stack
What I used to build the product layer (the underlying risk engine is internal team IP and is not described here):
| Layer | Tools |
|---|---|
| Web framework | Flask (Python) |
| Frontend | Tailwind CSS, vanilla JS |
| Auth | Authlib (Google OAuth), bcrypt, Flask sessions |
| SMTP (registration / approval / password reset notifications) | |
| Database | SQLite (users, sessions, approvals, submissions) |
| LLM API | OpenAI (chat + structured extraction over SSE) |
| RAG | SentenceTransformers (all-MiniLM-L6-v2) for incident retrieval |
| Web extraction | Jina Reader API for public-page content fetching |
| Knowledge graph | PyKEEN, NetworkX, PyVis (for the engine integration layer) |
| Data | Pandas, NumPy |
| WSGI | gunicorn (daemonized, PID-tracked, rotating logs) |
| Public access | ngrok with reserved HTTPS domain |
| Provisioning | Vagrant for VM-based dev environments |
Production status
Deployed on a shared Linux server, exposed publicly through a reserved-domain HTTPS tunnel, and used for internal evaluations and partner demos. The platform is part of an internal, pre-commercial project; the source code is private.
Screenshots
Landing — guided workflow, ~10 minute path from URL to risk report
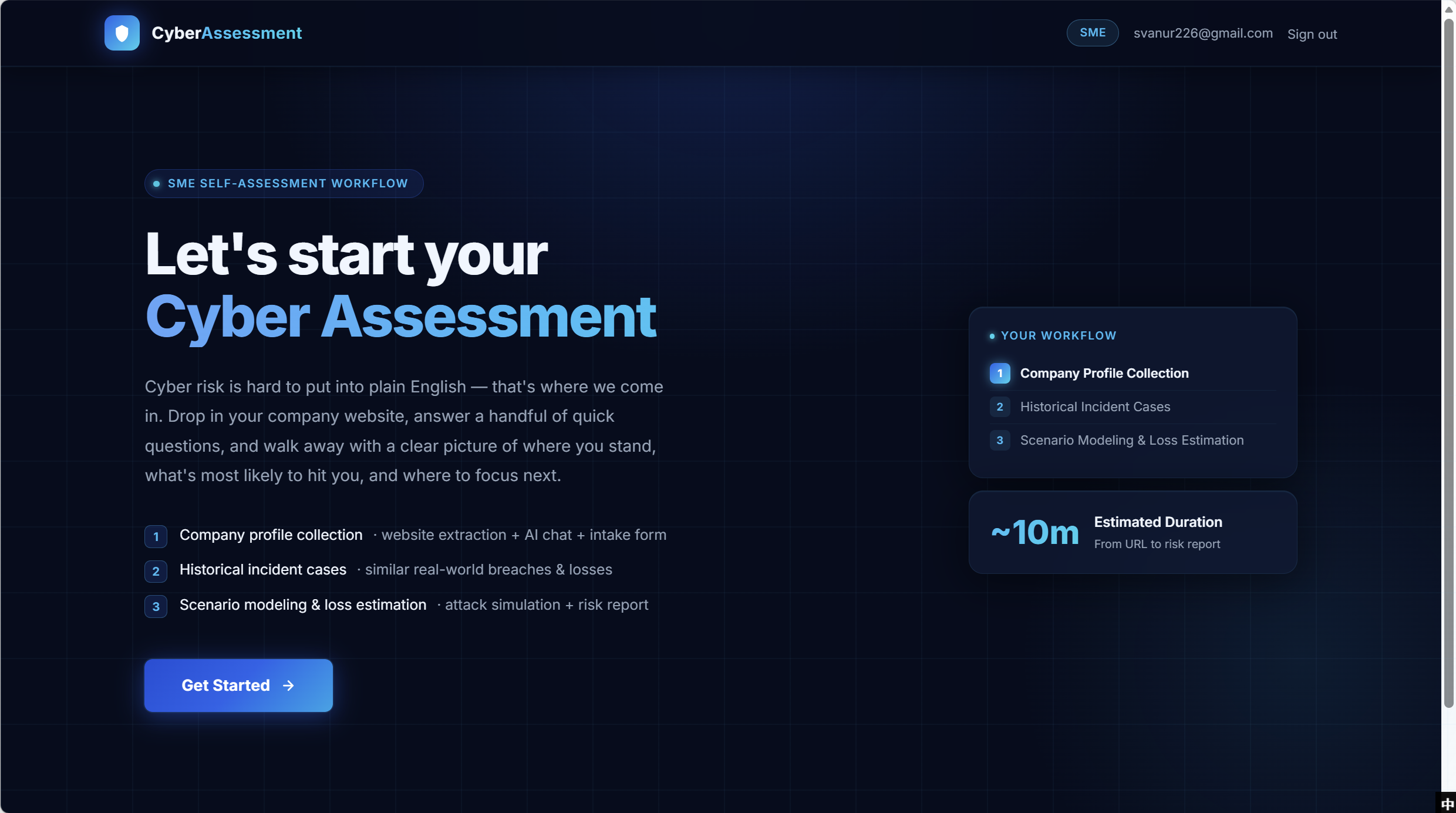
The landing page sets expectations in plain English: a one-line “drop in your company website, answer a few questions, get a risk picture” pitch up top, a three-step plan on the left, the same workflow mirrored as a Your Workflow progress panel on the right, and an explicit ~10m duration tile. The role badge (SME / Insurance) in the header is the persona-routing signal from the first screen.
Verification — confidence-coded review of auto-extracted fields
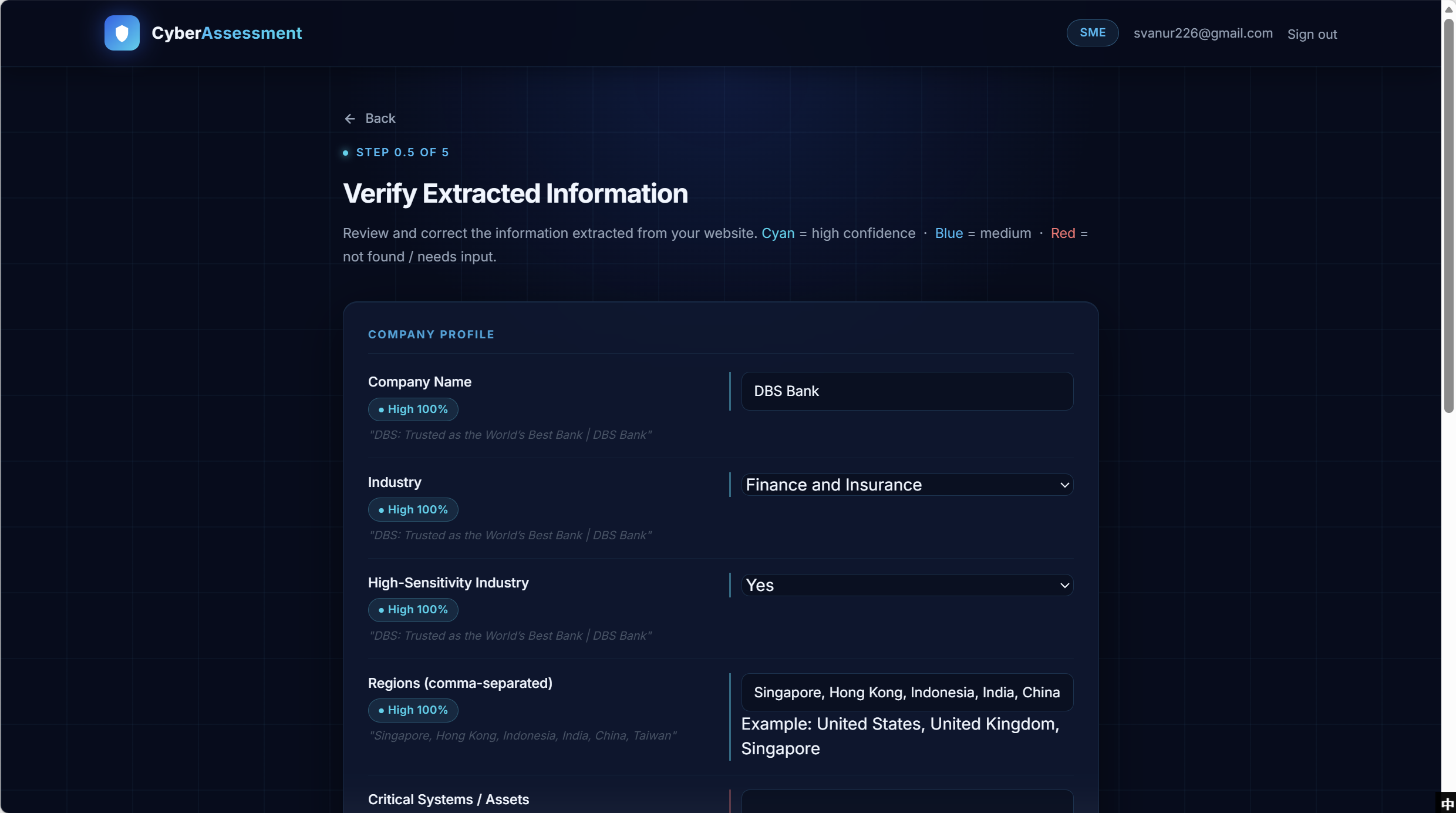
Auto-extracted fields land here with per-field confidence badges (Cyan / Blue / Red) and the underlying source snippet quoted beneath each value. Users scan instead of re-reading every line — they only edit fields the system flagged as uncertain.
Assessment Chat — conversational gap-filling with a live collected-fields panel
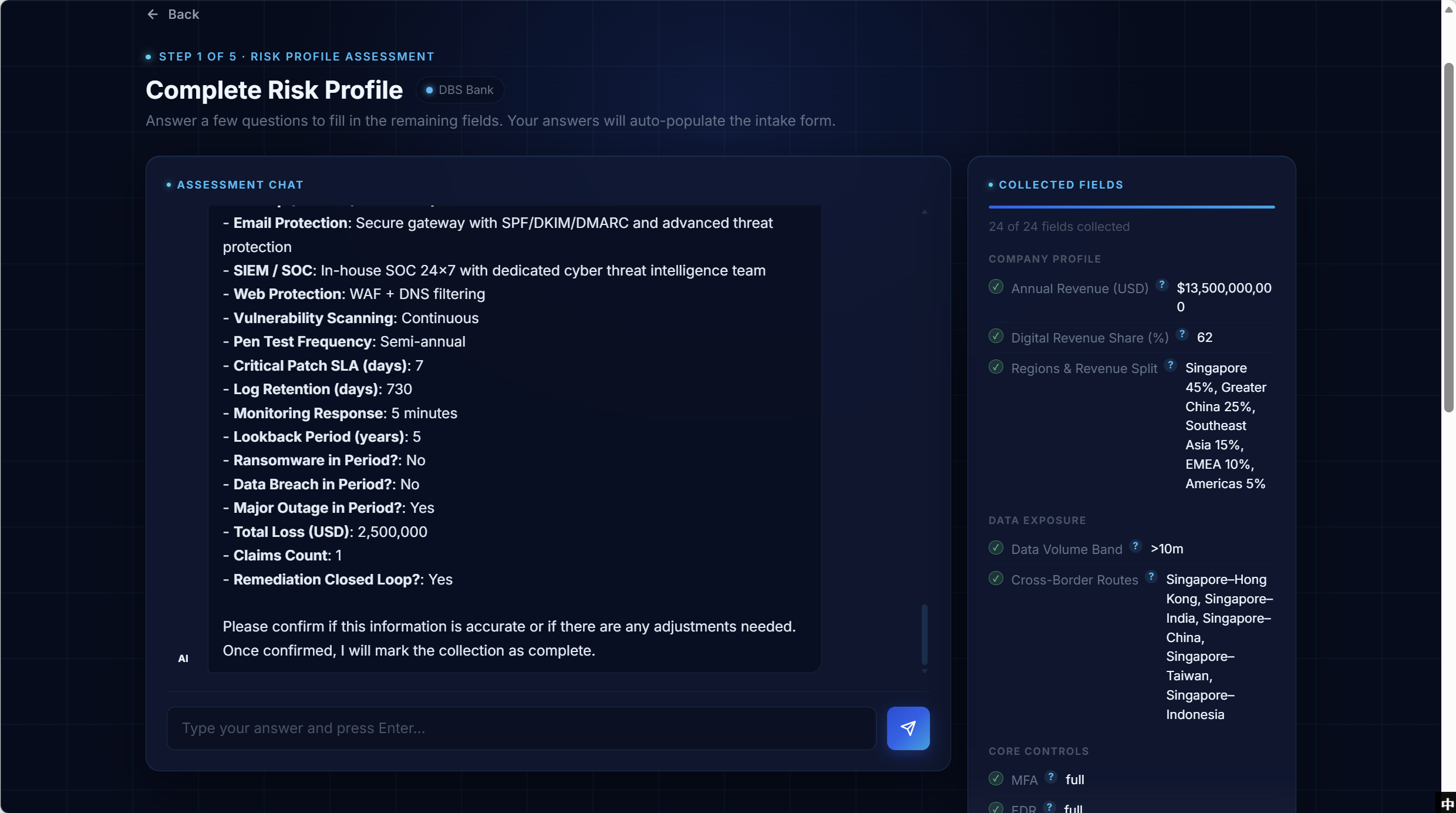
The conversational assistant collects the 22+ fields a public website doesn’t expose, grouped by topic so the user can batch their thinking. The right-hand Collected Fields panel updates in real time as each reply is parsed — by the time the bot says “please confirm”, the user has already seen exactly what’s been captured.
Historical Incidents — relevant past breaches for benchmarking
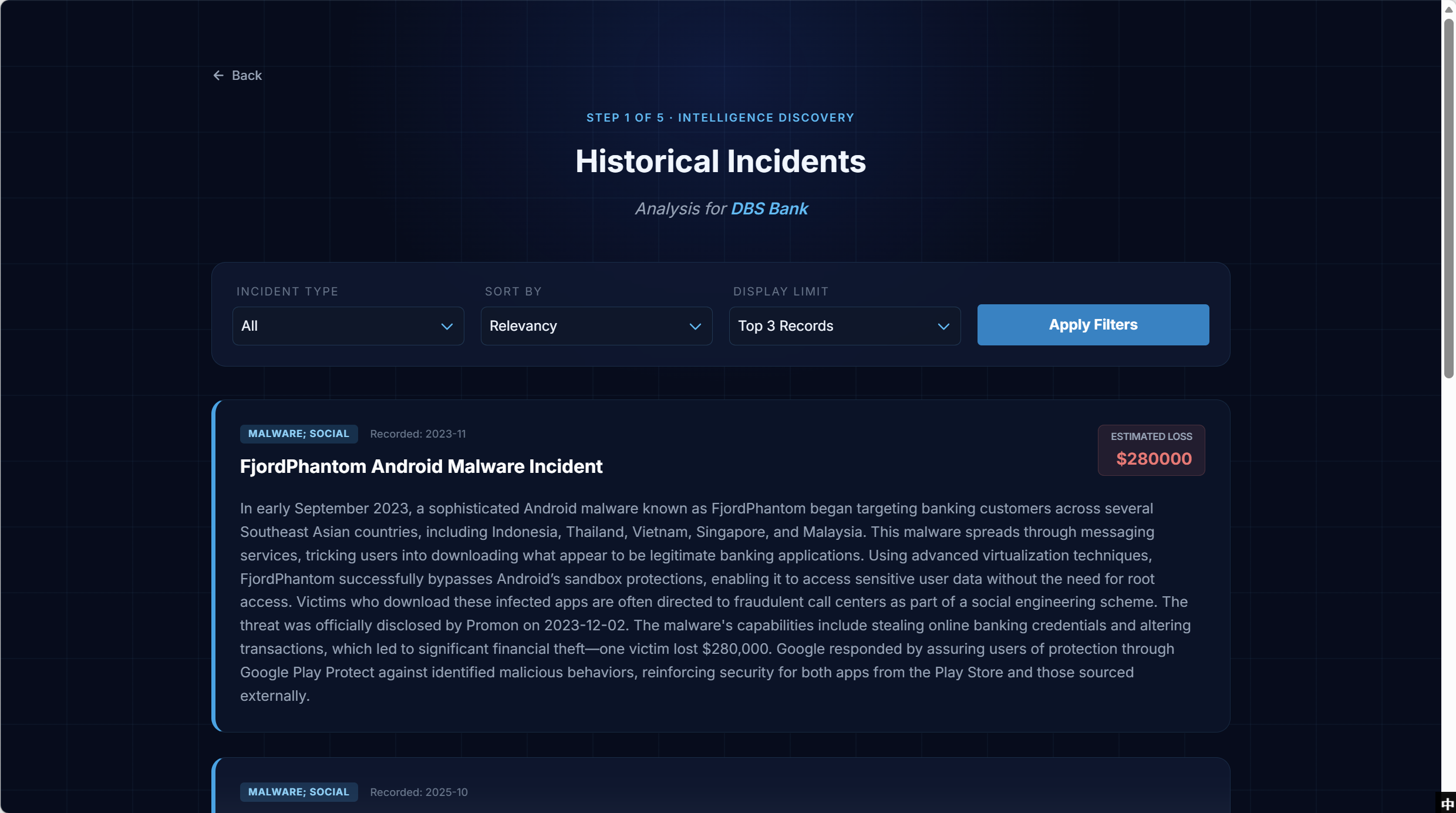
Each incident card shows the incident type, recorded date, estimated loss, and the full historical context — so the underwriter can see why a given past incident was retrieved as comparable, not just a number. Filters let the user widen or narrow the comparison set on the spot.
Risk Analysis Result — executive summary, tier distribution, system health
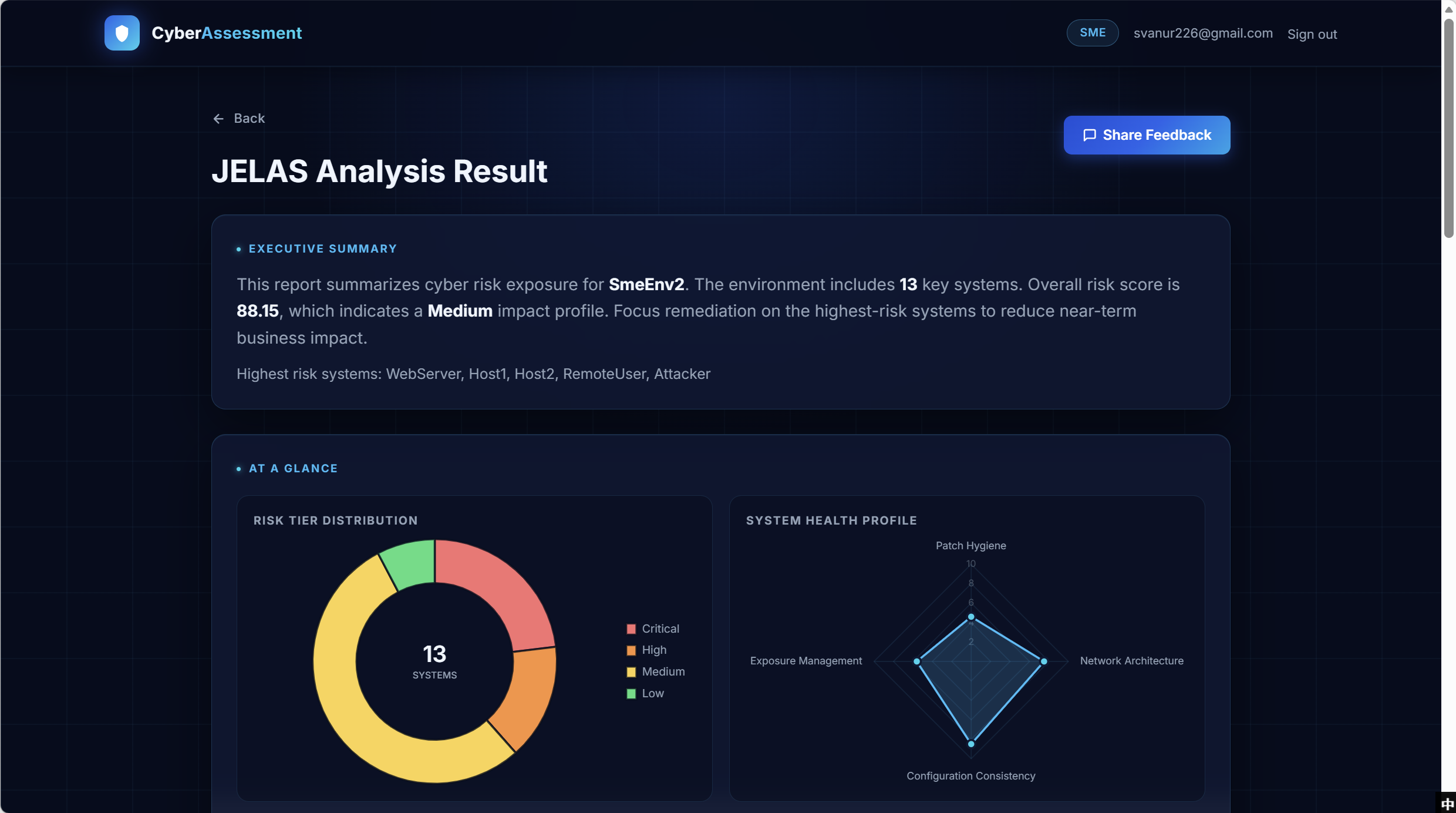
The result page leads with an Executive Summary (overall score, impact tier, named highest-risk systems) so an underwriter sees the headline within seconds. Below that, a Risk Tier Distribution doughnut and a System Health radar give a one-glance read of where the exposure sits before drilling into per-system findings. The pinned Share Feedback button is the entry point for the in-platform feedback loop.