背景
研究助理项目,应导师要求构建 政策证据知识图谱平台 —— 一个由三个相互配合模块组成的 monorepo,用于在气候政策科学文献上做 证据驱动的问答。
架构
平台被组织为三个通过 HTTP 通信的松耦合服务:
1. KG 后端(Python + Neo4j)
- 摄入:MinerU 解析 PDF → 结构化的
findings+tables→ 写入 Neo4j。 - schema 分离:表格不污染主体的 prose 图谱,而是由 finding 携带
table_refs指针,表格本身存放在独立的文件存储中。 - KG API 暴露:
papers / findings / evidence / tables / semantic / expand / community-summaries / graph-neighborhood / pipeline。 - 检索能力:向量语义检索、补全 schema 的跨语言检索、用
CommunitySummary节点承载跨论文的高层上下文。 - 后处理修复:元数据回填、分类纠正、表-证据拆分、review sheet 导出 —— 全部不需要重跑 LLM。
2. 受约束 Q&A Agent
Agent 是一个 受约束的摘要器,不是自由聊天 bot —— 它只能基于 KG 检索结果作答。
- 五路检索路由:
local / semantic / hybrid / expand / community_summaries。 - 复杂问题自动拆解为
sub_queries;多 driver 的问题按 driver 自动拆分,然后去重合并。 - LLM 关键词抽取(gpt-5.4-mini,结构化 JSON 输出)与正则兜底并行执行。
- 强制引用规则:每条实质性论断都必须带引用;当证据不足时,Agent 显式说明「不足以回答」,而不是产生幻觉。
- 每条回答都附带 程序化的置信度分数(双轨制,见下文)。
3. Web 前端(React + Vite)
- 流式问答 + 会话持久化(
localStorage,保留最近 30 条会话,按 Today / Yesterday / Last 7 Days / Older 分组 —— Claude 风格的侧边栏)。 - 知识图谱可视化:基于
react-force-graph-2d,以节点为中心做扩展(Paper / Finding / Driver / Outcome),支持搜索、按类型筛选、点击展开邻居,以及从任意 knowledge card 或 evidence library 条目「在图中查看」的跳转。 - 证据库:双视图(按 Paper / 按 Finding)方便浏览底层语料。
- 置信度卡片:总体分数 + 矛盾标记;展开后可并排展示 evidence-side / answer-side 子分数、Claim 类别拆分(📘 Extract / 💭 Extrapolate)以及 LLM-judge vs. heuristic 对比。
- 反馈闭环:每条回答下都有 👍 / 👎;反馈 + 完整的置信度快照持久化到 SQLite(
agent/data/feedback.db)—— 直接用于离线权重校准。
反幻觉控制
多层校验栈,确保答案完全可追溯:
| 层 | 检查内容 |
|---|---|
| 引用白名单 | Agent 只能引用 KG 中存在的论文。 |
| 方向冲突检测 | 与已知 KG 事实矛盾的论断会被标记。 |
| 单位归一化 | 数值单位先归一化再比较;不一致会上报为冲突。 |
| NLI / LLM-as-judge 事后审查 | 拼装出的回答可走可选的 fallback 校验。 |
双轨置信度评分
两条独立打分轨道,加权得到总分:
- Evidence side(4 维):来源可信度、覆盖度、时效性、冗余度。
- Answer side(5 维):一致性、推理距离、claim 密度、引用多样性、Extract / Extrapolate 平衡。
用户的反馈快照会驱动 OLS 校准 与 特征权重热更新,让评分函数随真实使用持续适应。
端到端流水线
PDF 解析 → finding 抽取 → snippet-claim 对齐
→ Neo4j 摄入 → LLM-as-judge 自动评测
(准确性、可追溯性、一致性)自动评测模块从三个维度对 Agent 回答打分,支撑系统的迭代式改进。
全局 chrome(出现在每个页面)
每条路由都会渲染:
- 品牌区 —— 气候政策证据维基 / Climate Change Wiki(点击回
/)。 - 语言切换 —— 中 / EN(切换 URL 前缀,连带切换内容集)。
- 语料量徽章 —— 实时显示当前库内论文数(例如 163 篇)。
- 全局菜单 —— 汉堡按钮展开 Q&A、知识图谱、证据库、Topic 浏览器、Admin(登录后)、Settings。
- 会话持久化指示点 —— 正在写入本地存储时显示一个小圆点。
主页 / 着陆页(/)
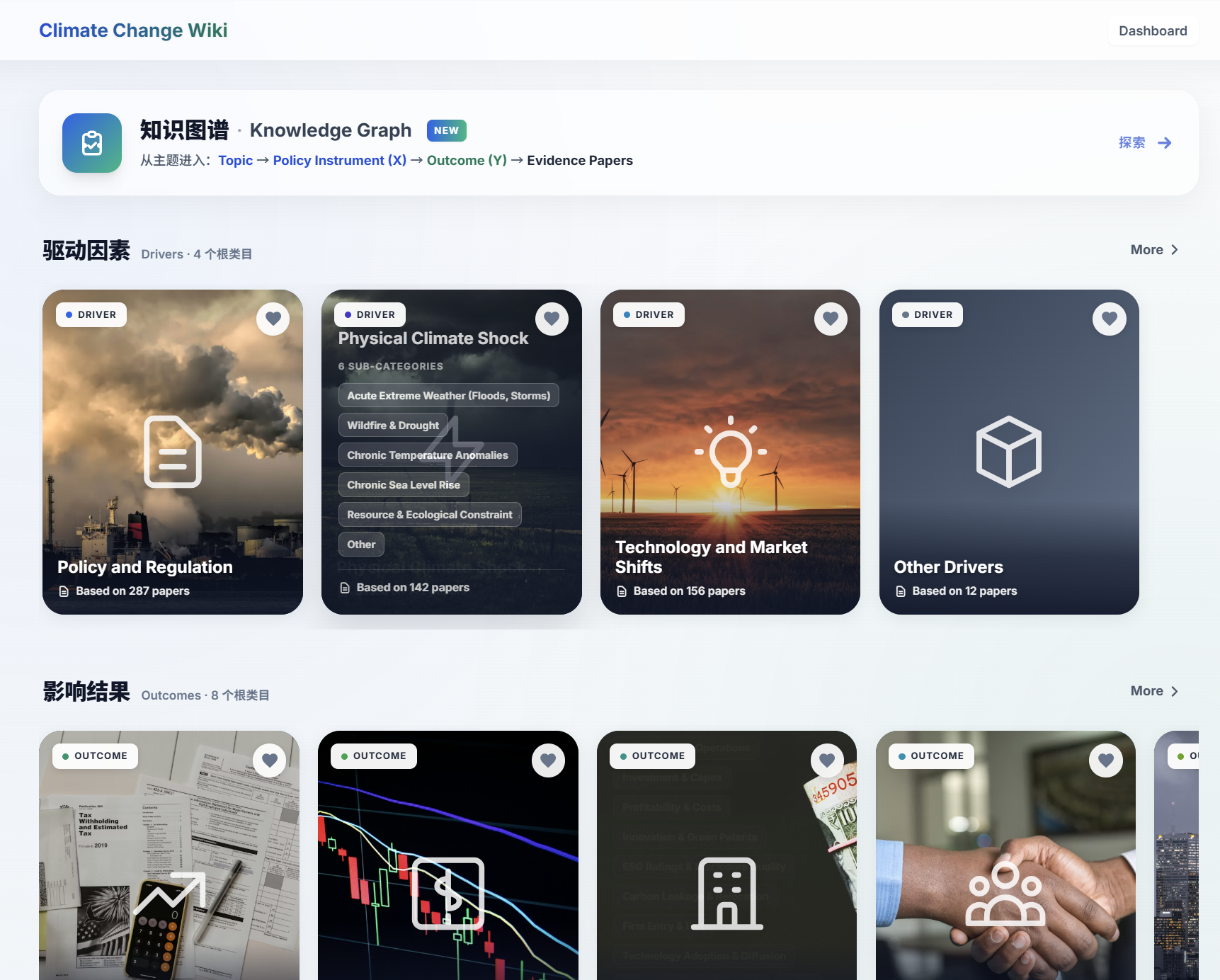
主页直接暴露了平台的核心 schema:每个问题都从选择一个 Topic (X) → Policy Instrument → Outcome (Y) 起步,最终落到一组 Evidence Papers。Drivers 与 Outcomes 是两大顶级分类 —— drivers 拆为 4 个根类目(Physical Climate Shock 进一步拆为 6 个子类目:Acute Extreme Weather、Wildfire & Drought、Chronic Temperature Anomalies、Chronic Sea Level Rise、Resource & Ecological Constraint、Other),outcomes 拆为 8 个根类目。每张卡都展示了底层论文数(287 / 142 / 156 / 12 ……),让用户在点入之前先掂量证据密度。
页面功能:
- 知识图谱入口卡 —— 介绍 X → Y → Evidence Papers 的遍历模式,探索 → 按钮跳转到图视图。
- Drivers 一栏 —— 4 张根类目卡(Policy and Regulation 287 篇、Physical Climate Shock 142、Technology and Market Shifts 156、Other Drivers 12)。Physical Climate Shock 卡片展开 6 个子类目。
- Outcomes 一栏 —— 8 张根类目卡(Tax & Public Finance、Investment & Capital、Profitability & Costs、Innovation & Patents、ESG Rating & Reputation、Carbon Leakage、Firm Entry / Exit、Technology Adoption & Diffusion)。
- 每卡论文数徽章 —— 让用户点入前先掂量证据密度。
- 收藏开关 —— 每张卡右上角的爱心图标,收藏后会被钉到快速访问条。
- 搜索 / 探索栏(右上) —— 直达 Q&A 并把搜索词预填进去。
- Dashboard 入口 —— 有相应权限的用户才能看到的管理面板。
Q&A 界面(/qa)
用途: Agent 的主入口。用户提问后,系统按意图分类挑选层级(T1 – T4,详见下面四个子章节),渲染对应的结构化回答。
页面功能:
- 左侧栏 —— 会话历史。 最近 30 条对话按 Today / Yesterday / Last 7 Days / Older 分组(Claude 风格),每行显示首条用户消息作为标题。
- 新对话按钮 位于侧栏顶部。
- 侧栏收起按钮 (← / →)用于窄屏。
- 主面板 —— 流式问答。 顶部回显用户提问,下方逐步渲染 Agent 的分层回答;走 SSE,所以第一张卡片在其余内容计算之前就先出现。
- 层级路由 —— 通过意图分类自动路由到 T1 / T2 / T3 / T4(详见下面的子章节)。
- 底部输入栏 —— 支持多行,Shift-Enter 换行,回车发送。
- 可信度卡 —— 一直钉在回答末尾(总分 + 双轨拆分)。
- 逐条反馈 chip —— 👍 / 👎 + 可选评论。
- 复制 / 分享菜单 —— 每条回答可生成分享链接,重建完整对话状态。
T1 概念检索(「X 是什么 / X 有哪些」)
覆盖: ~10% 的提问。输出约定: 只生成知识卡片页 —— Agent 的任务是 只回答概念本身、不多说,并引用多篇文献。
对于概念类提问(如 「什么是碳定价?」),Agent 不是给一段平铺的话,而是渲染一份 结构化多卡片 的回答页。下面按 数字 / 页面顺序 走查每张卡片,每张截图嵌在它首次出现的卡片下。
C0 —— 核心定义 + 权威引用
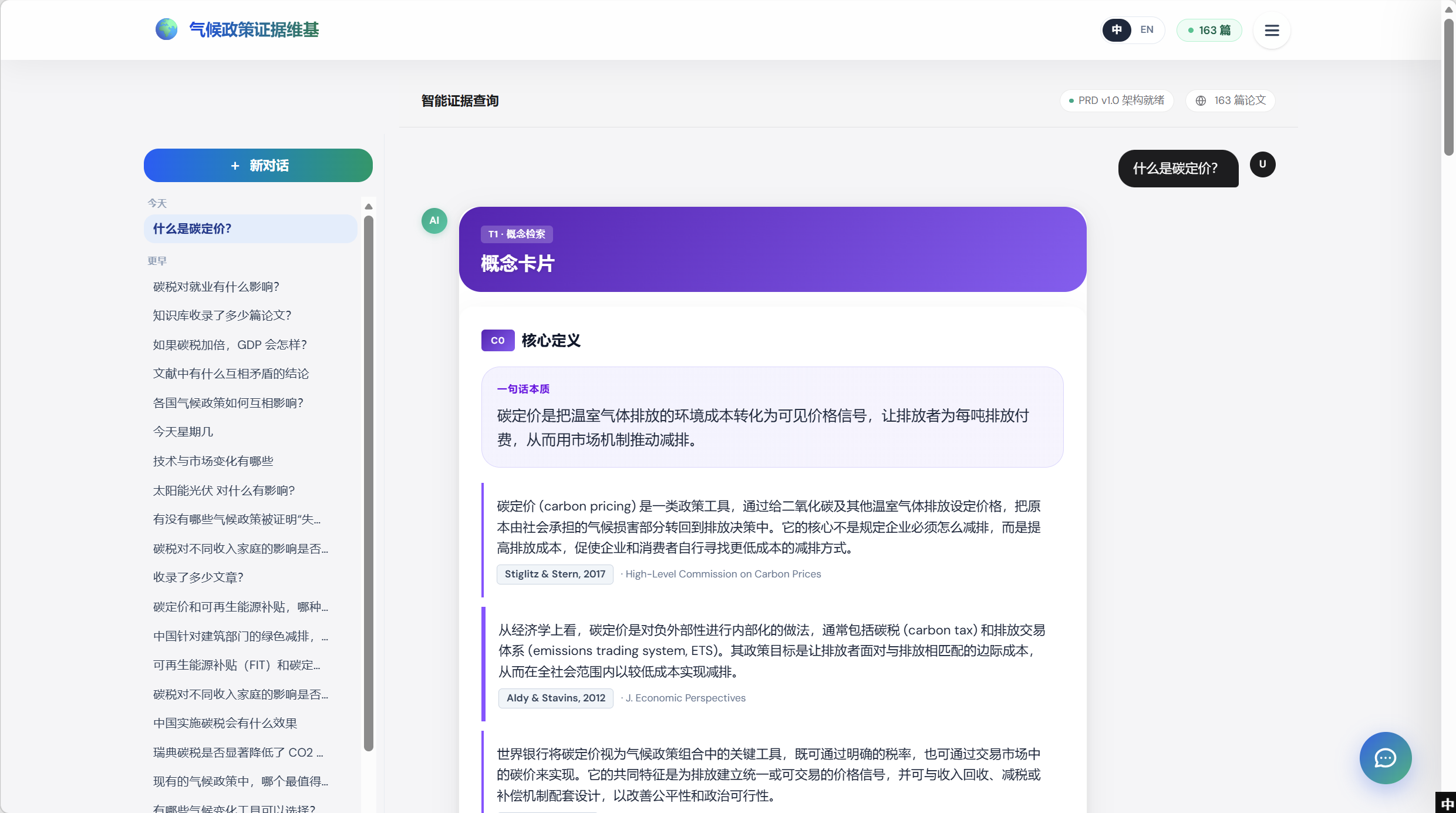
C0 以 一句话本质 开场(“碳定价把温室气体排放的环境成本转化为可见价格信号,让排放者为每吨排放付费”),然后展开成有权威学术定义的多段表述,每段都带引用 chip 落到 KG 中的具体论文 —— 没有任何无溯源的自由发挥。页面卡片插槽顺序是固定的,下面这些卡片永远按同一顺序出现,只是每个查询里的内容不同。
C2 —— 全球实施图景
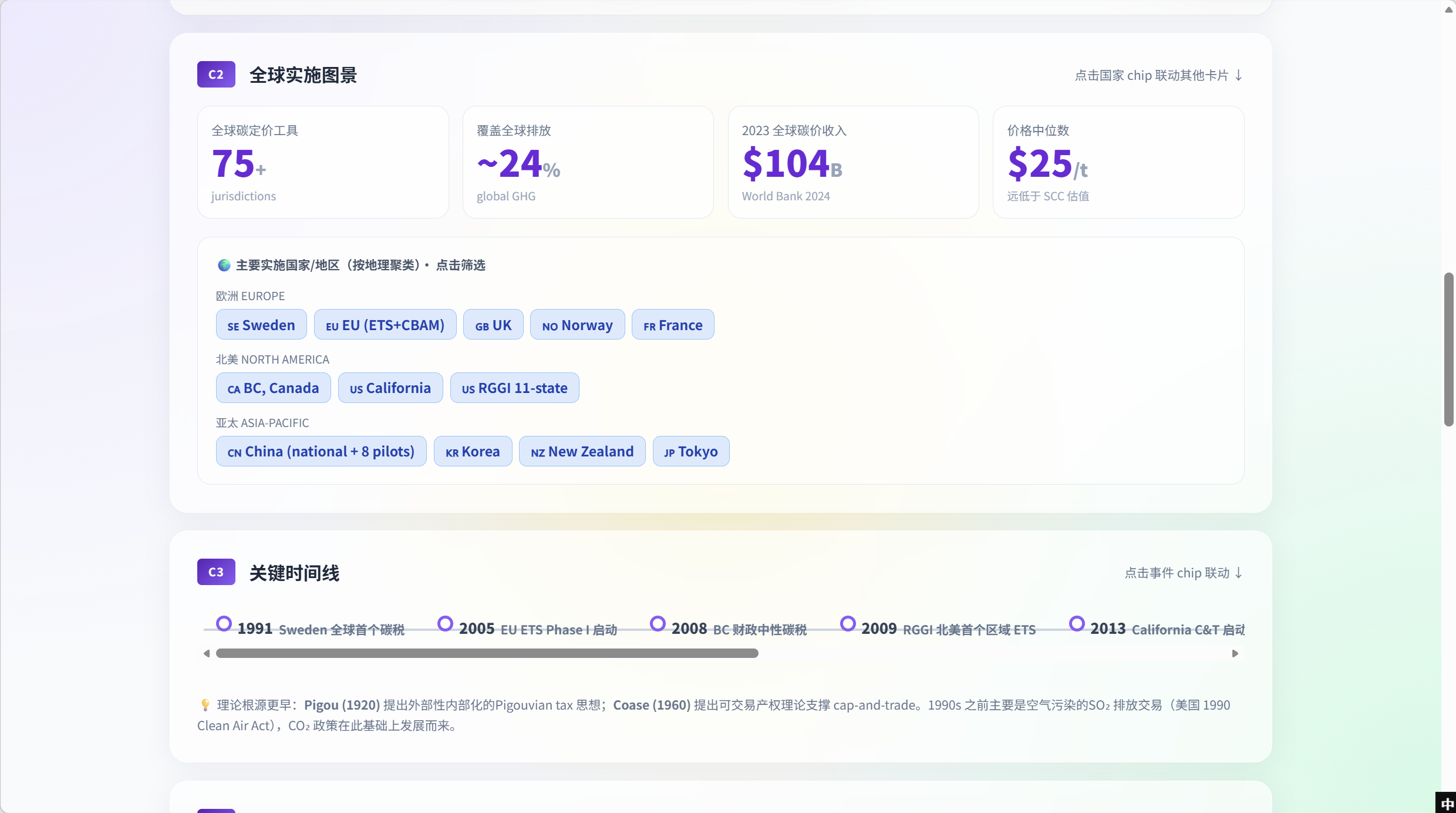
C2 展示概念的实际规模 —— 75+ 司法管辖区、~24% 全球 GHG 覆盖、$104B 2023 收入、$25/t 中位价(远低于 SCC 估值)。KPI 下方按地理聚类把司法管辖区渲染成可点击 chip(欧洲 / 北美 / 亚太)。点击 China 后页面所有其他卡片会被筛到 China 相关证据;再点一次清除筛选。
C3 —— 关键时间线
政策里程碑按时序渲染成横向时间条:1991 Sweden 全球首个碳税 · 2005 EU ETS Phase I · 2008 BC 财政中性碳税 · 2009 RGGI · 2013 California C&T 等。底部脚注点出理论根源(Pigou 1920、Coase 1960)和 1990 美国 Clean Air Act SO₂ 排放交易作为前身。点击任意里程碑 chip 会打开侧抽屉,加载对应日期窗口标记的论文证据集合。
C4 —— 概念关联图
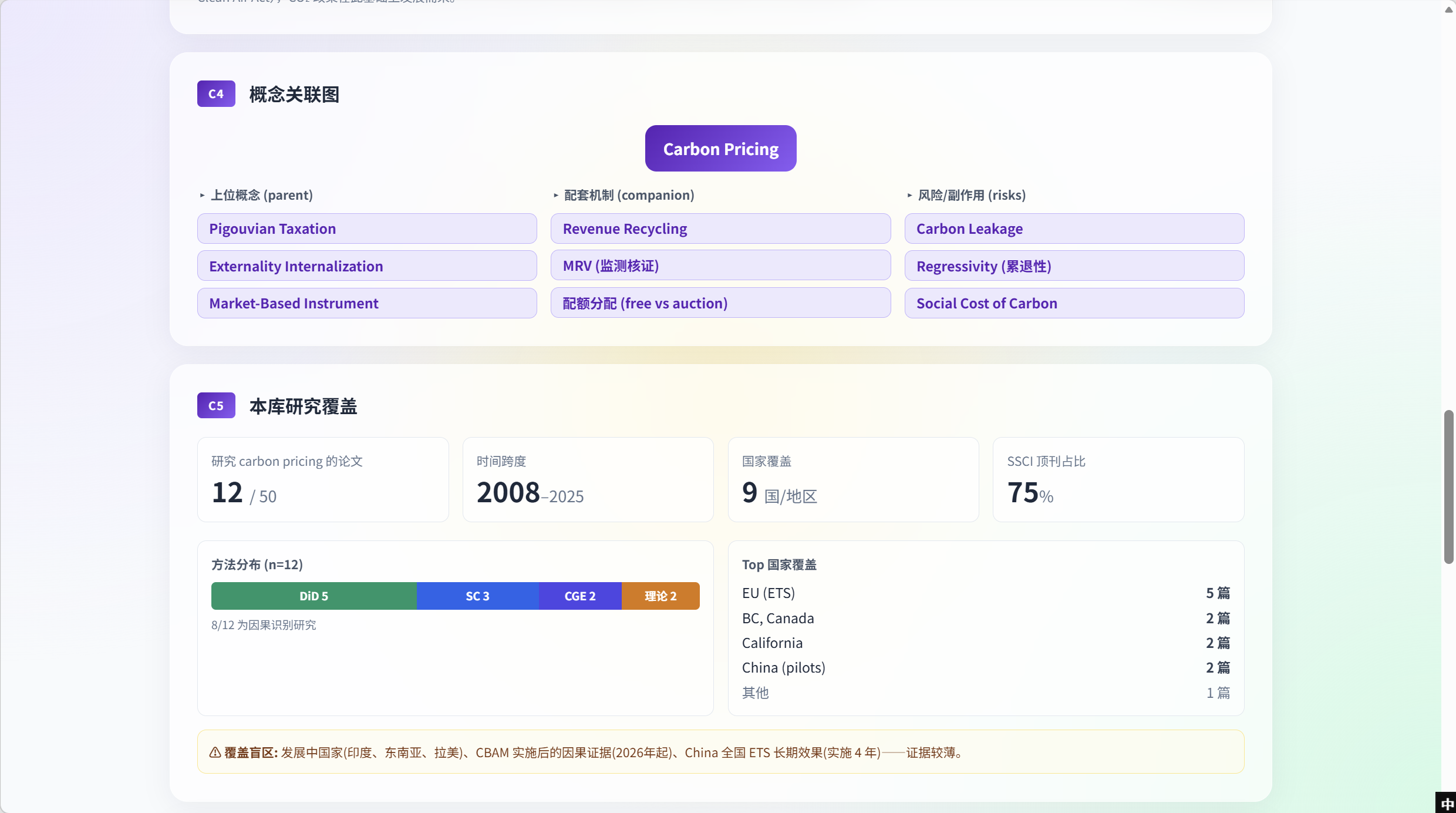
C4 把概念放进它的概念邻域 —— 上位(Pigouvian Taxation、Externality Internalization、Market-Based Instrument)、配套机制(Revenue Recycling、MRV、free-vs-auction 配额)、风险(Carbon Leakage、Regressivity、Social Cost of Carbon)—— 边都直接来自 KG 里的有类型关系。每个节点可点击:点击 Revenue Recycling 路由到该配套概念的新 T1 查询,并保留父概念面包屑。
C5 —— 本库研究覆盖
元卡片。它量化了知识库 本身 对该概念的覆盖:12 / 50 篇、2008–2025、9 个国家、75% 顶刊占比、方法分布 DiD 5 / SC 3 / CGE 2 / 理论 2(8/12 为因果识别)。Top 国家覆盖列出 EU (ETS) 5 篇、BC Canada 2 篇、California 2 篇、China (pilots) 2 篇、其他 1 篇。底部用警示框 显式点出覆盖盲区 —— 发展中国家(印度、东南亚、拉美)、CBAM 实施后的因果证据(2026 年起)、China 全国 ETS 长期效果(实施 4 年)。这是反幻觉系统的反向操作 —— 在用户开口之前主动告诉他系统不知道什么。
证据卡片 —— 逐篇论文
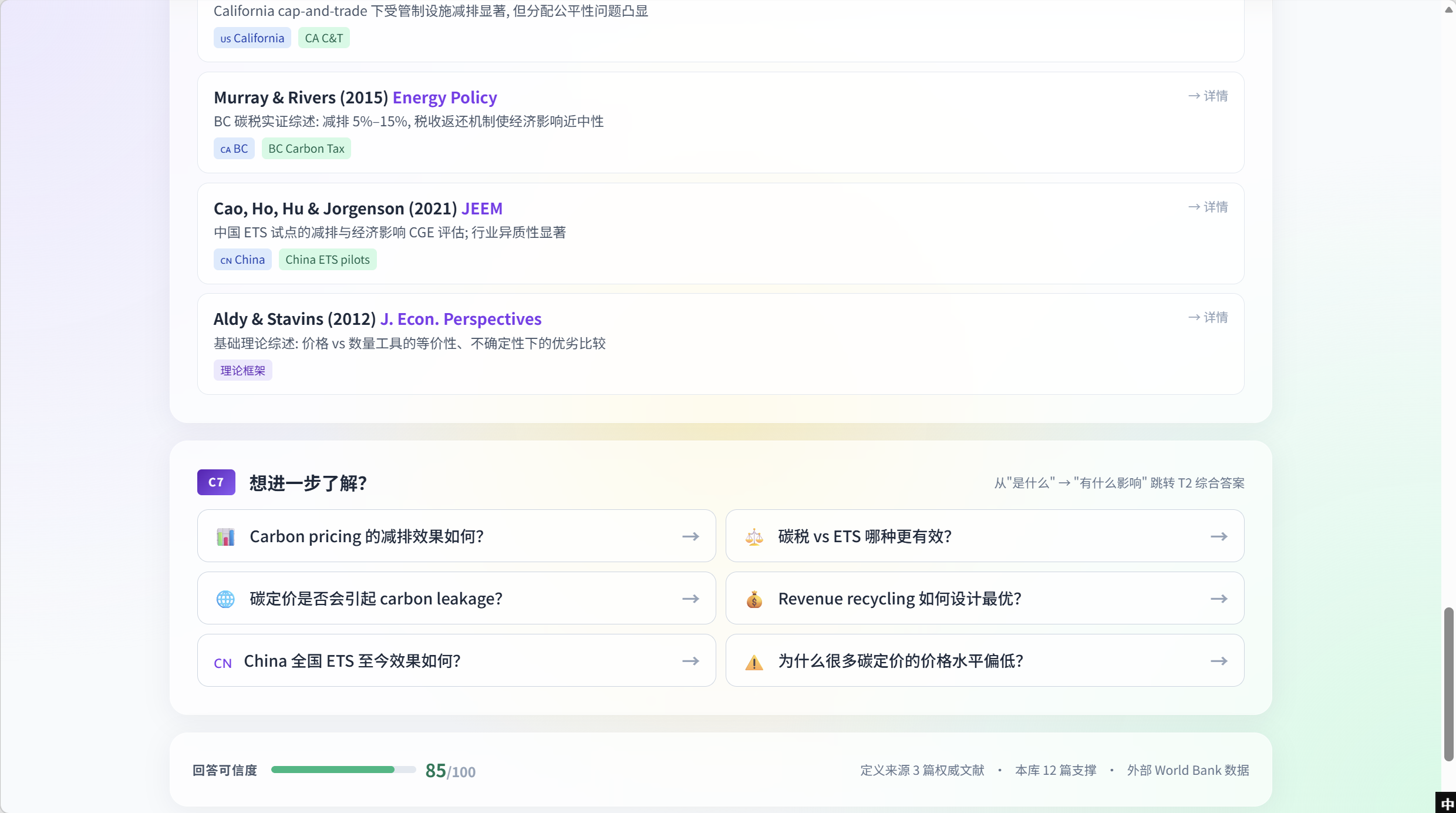
C5 之后页面渲染 逐篇论文证据卡 —— 每张卡对应一篇相关本库论文,带核心结论、国家 / 工具标签,以及跳进证据库完整 finding 页的入口。截图中的例子:California cap-and-trade 下受管制设施减排显著但分配公平性问题凸显(CA C&T);Murray & Rivers 2015(Energy Policy) —— BC 碳税实证综述(减排 5%–15%,税收返还使经济影响近中性);Cao Ho Hu Jorgenson 2021(JEEM) —— 中国 ETS 试点 CGE 评估;Aldy & Stavins 2012(J. Econ. Perspectives) —— 基础理论综述。
C7 —— 想进一步了解
C7 是 追问 chip 卡 —— 系统对 接下来用户自然会问什么类型问题 的理解。例子里给出:「Carbon pricing 的减排效果如何?」、「碳税 vs ETS 哪种更有效?」、「碳定价是否会引起 carbon leakage?」、「Revenue recycling 如何设计最优?」、「CN China 全国 ETS 至今效果如何?」、「为什么很多碳定价的价格水平偏低?」。每个 chip 带类型 —— 前缀决定路由到哪个回答层级(这里大多落到 T2,因为 C7 在 T1 中的职责就是从「定义」桥接到「影响 / 对比」)。
可信度条(页面页脚)
页面最底部:回答可信度 85/100,附溯源拆分 —— 定义来源 3 篇权威文献 · 本库 12 篇支撑 · 外部 World Bank 数据。这个条在 T1/T2/T3 的所有回答中都固定钉在末尾;85 的具体拆分见下方的 T1 可信度拆分 子章节。
T1 路由 —— Agent 何时选概念卡模式
- 意图分类器先跑一遍查询(gpt-5.4-mini,结构化 JSON 输出):分桶到
definition / impact / comparison / status-quo / policy / how-to / contested。只有definition桶才路由到 T1。 - 触发 T1 的查询模式:“what is X?”、“define X”、“X 是什么?”、“X 的定义”、单词查询(“碳定价”)。
- 歧义查询(单一歧义词且无动词)触发消歧预流:Agent 渲染一张小的选择卡,列出候选语义(例如 “carbon pricing” 下的 carbon tax vs ETS vs cap-and-trade)并让用户挑。
- 严格只引用模式:当 KG 中没有 ≥ 2 篇权威定义时,C0 不会触发。此时 T1 降级到一段说明 “本库不含该概念的标准定义,下面是我们能找到的最接近的权威描述” —— 永远不会幻觉一个定义出来。
静态截图看不到的交互行为
- C2 国家 chip 是双向筛选 —— 点击 China 把页面所有其他卡片筛到中国相关证据;再点一次清除。
- C3 时间线 chip 点击后打开侧边抽屉,加载该时期的证据子集(按里程碑日期窗口标记的论文)。
- C4 图节点 可点击 —— 点击 Revenue Recycling 路由到该配套概念的新 T1 查询,并保留父概念。
- 引用 chip(页面任何地方)鼠标悬停展示被引片段(不只是论文标题),点击进入证据库的完整 finding 页。
- C7 追问 chip 都是有类型的:每个前缀路由到特定回答类型 ——
T2(影响)、T3(对比)、T4(机制)、T5(政策含义)。
T1 可信度拆分
例子里的 85/100 按前面提到的 双轨制 拆开:
- Evidence side(权重 40%)—— 来源可信度 95、覆盖度 88、时效性 82、冗余度 92。时效性略低是因为最强的经典引用来自 2012 和 2017。
- Answer side(权重 60%)—— 一致性 90、推理距离 78(低 —— 大部分主张是直接 extract 的)、claim 密度 85、引用多样性 80(多以 OECD 为锚 —— 已作为覆盖 caveat 提示)、Extract / Extrapolate 平衡 75(以 extract 为主 —— 分值反映出 “解释力强但偏保守” 的语气)。
- 任意 answer-side 维度跌破 70 时,可信度卡上会出现
需注意标记。
T2 综合性问题(影响 / 对比 / 叠加 / 区域)
覆盖: ~40% 的提问 —— 体量最大的一档。形如 「X 对 Y 有影响吗?」、「哪个 X 更好?」、「X+Y 叠加如何?」、「中国 X 会怎样?」 的所有问题。检索分两层:
- 第一层 —— 综述文献语料。 先在精挑过的 Zotero 库(review / meta-analysis 篇)里检索头部答案(「共识层」)。
- 第二层 —— 单篇文献语料。 再在完整逐篇语料里检索支撑性的具体发现(「细节层」)。
两层 整合成一份结构化回答。下面按页面顺序走查回答里的每个组成部分,每张截图嵌在它首次出现的组件下。
来源质量仪表(页面顶部)

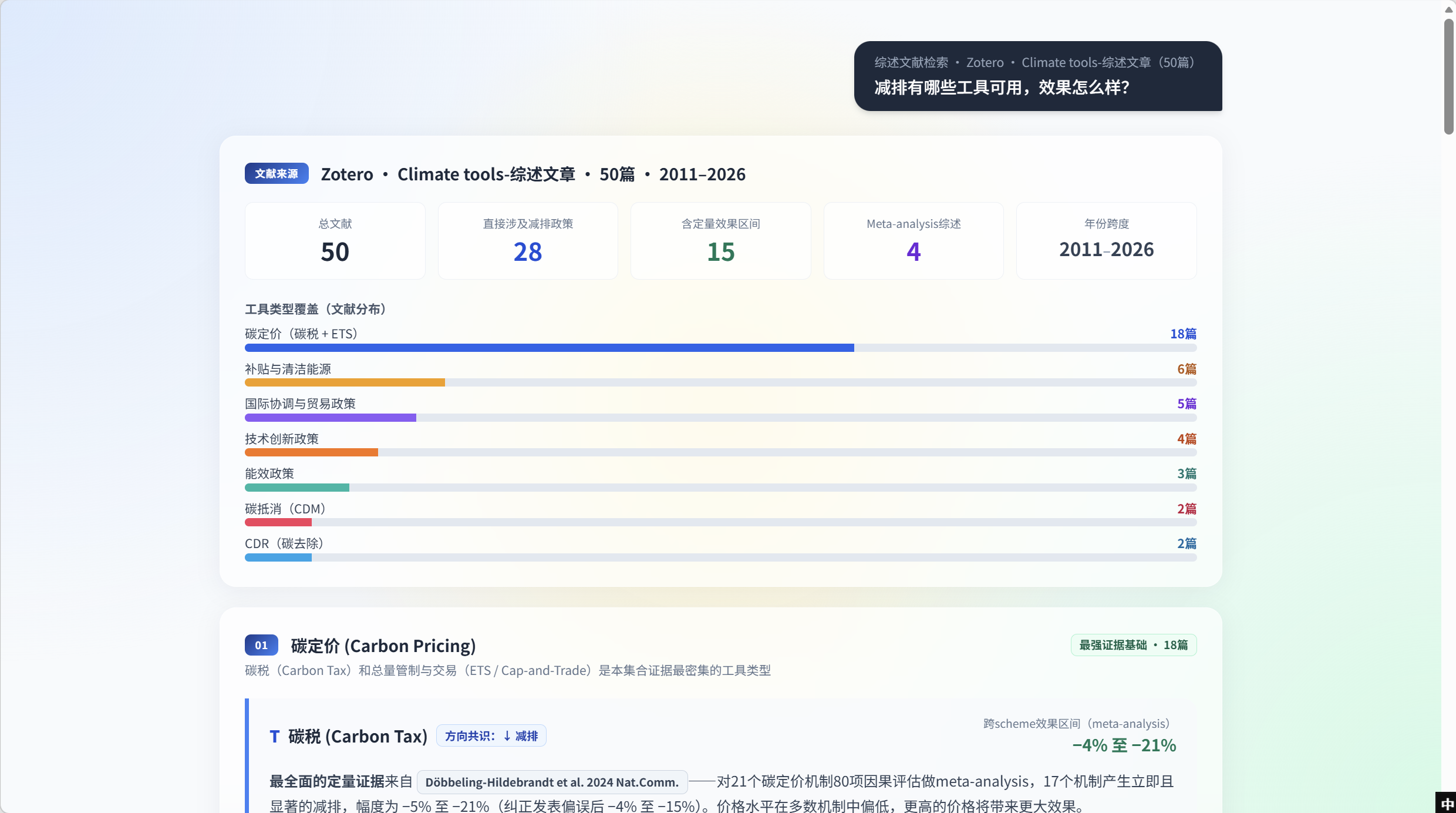
T2 回答先用 来源质量仪表 开场 —— 不只是 答案是什么,而是先告诉用户 证据底子怎么样。页面顶部标头写着 综述文献检索 · Zotero · Climate tools-综述文章(50 篇) —— 明示这次回答从哪个语料里检索。下方五个 KPI tile:总文献 50 · 直接涉及减排政策 28 · 含定量效果区间 15 · Meta-analysis 综述 4 · 年份跨度 2011–2026。任何主张前,用户先看清证据规模与形状。
工具类型覆盖条形图
紧跟仪表下方,一条横向条形图,把 50 篇按工具类目拆开:碳定价 18 篇、补贴与清洁能源 6 篇、国际协调与贸易 5 篇、技术创新 4 篇、能效 3 篇、碳抵消 / CDM 2 篇、CDR 2 篇。视觉排序让每个工具的证据密度一眼可读,也提前告诉用户下面哪些工具章节会证据充分、哪些会偏薄。
01 章节 —— 碳定价 (Carbon Pricing)
第一个逐工具章节紧接在覆盖条形图下方。01 —— 碳定价 拿到最强证据 banner(18 篇)。其首行是 碳税 (Carbon Tax) —— 方向共识 ↓ 减排,meta-analysis 效果区间 −4% 至 −21%。主引用 chip 是 Döbbeling-Hildebrandt et al. 2024 Nat.Comm.,一行摘要说明该 meta-analysis 对 21 个碳定价机制做了 80 项效果评估,其中 17 个机制产生立即、显著的减排(幅度 −5% 至 −21%,纠正发表偏误后 −4% 至 −15%),多数机制价格偏低,更高价格带来更大效果。
02 – 07 章节(其他工具类目)
完整的 T2 回答会继续为语料里 ≥ 2 篇的每个工具类目展开并列章节。每个章节都以「最强单篇引用 banner」开场,列出 2–4 篇支撑发现,并以一张内部小子表收尾,列出该类目下的所有子工具(例如碳定价拆为碳税和 ETS 两行;补贴按技术拆分)。
- 02 —— 补贴与清洁能源。 生产税收抵免、投资税收抵免、EV 补贴、FIT 机制。最强引用:Hahn 2025;定量区间涵盖 MVPF 与减排成本两个维度。
- 03 —— 国际协调与贸易政策。 CBAM、气候俱乐部、进口关税、行业协议。
- 04 —— 技术创新政策。 R&D 补贴、政府采购、示范项目。
- 05 —— 能效政策。 标准、标签、改造项目 —— 显式带上工程预测易高估的 caveat。
- 06 —— 碳抵消 / CDM。 整个章节带红色警示边框,因为语料共识是负面(额外性失败)。
- 07 —— CDR(碳去除)。 作为补充工具处理 —— 章节抬头明示证据稀薄、不确定性高。
跨工具综合对比表
走完 02–07 章节后,页面给出 跨工具综合对比表 —— 整份回答的综合面。每个工具一行,给出方向(↓ 减排 / ↑ 增排 / ~ 中性)、定量区间、最强引用集合,以及一行 核心 caveat —— 那种读者最容易漏看的「但是…」。CDM 行用红色高亮:本集合的发现是它有一种 失败模式(52% 以上无额外性 → 全球 CO₂ 净增加),系统用视觉强化、而不是把它埋在散文里。最底部的 政策组合 行(方向 ↓↓)展示工具组合优于单一工具,引用 Blanchard et al.、Peñasco 2021、Stiglitz 2019。
证据缺口卡片(页面页脚)
对比表下方的 证据缺口卡片 是元层的诚实 —— 四个被点名的盲区,每个都带支撑「我们知道我们不知道」的引用:
- 发展中国家专项证据 —— 语料偏 OECD,中国 / 印度 / 东南亚的因果证据稀薄(Döbbeling-H 2024 明说)。
- 政策组合的因果识别 —— 现有证据大多是单一工具评估,组合增量效果、组合 vs 各工具之和的问题缺乏严格因果研究(Perino 2025 叠加框架是理论贡献还需实证检验)。
- 长期 10 年+ 效果 —— 多数因果研究覆盖政策实施后 3–8 年,投资泄漏、技术锁定等长期效应证据稀薄(Verde 2020 明确列为最优先的未来研究方向)。
- 气候适应工具 —— 语料几乎全部聚焦 减排 mitigation,适应 adaptation 政策效果评估基本缺失(仅有 Carleton et al. / Ferreira 等分析框架,无系统综述)。
把这些缺口和对比表并列放出来,让 Agent 自己的覆盖边界成为回答的一部分,而不是潜伏成下游的沉默幻觉。
筛选与交互
- 年份滑块 位于仪表板上方,可以把语料限制在某个时间窗(如只看 2018 年之后)。效果区间和工具覆盖会实时重算。
- 筛选按钮:仅 meta-analysis、仅因果识别、仅 OECD / 仅非 OECD、仅 peer-reviewed 顶刊。每个筛选会先展示筛出的论文数再应用。
- 对比表可排序 —— 按方向(共识优先)、效果幅度、引用数、发表年份排序。
- 引用 chip 点击进入论文完整 finding 页面;工具章节锚点 在左侧栏内提供,允许直接跳到 02 补贴 等章节而不必滚动。
T2 路由 —— 何时触发
- 触发:多工具 / 影响 / 对比意图,例如 “X 效果怎么样?”、“哪种政策更有效?”、“有哪些 X 工具?”、“compare X and Y”。
- 降级到 T3(定性对比):任何被对比的工具语料 < 3 篇时,系统拒绝渲染统计上撑不住的对比行。
- 空行策略:用户明确问到、但语料中无证据的工具,渲染为 “证据缺失 —— 参见 C5 覆盖卡” —— 不会被静默丢弃。
跨论文综合逻辑
- 效果区间 每行来自一次 meta 聚合:所有在范围内论文的最低 / 最高汇报效果,按样本量加权、按标准误反加权。单论文行展示原始区间并带
n=1标记。 - 方向共识(↓ / ↑ / ~)标签要求 ≥ 60% 论文同向。低于 60% 时整行被标记为
mixed evidence,两个方向并排展示。 - 红色高亮 是自动的 —— 任何「共识方向」与政策原本意图相反的行(例如本应减排却 增排 的碳抵消机制)会得到红边框 + 红字。用户不需要从散文里捕捉到这一点。
- 证据缺口卡片 由另一条并行通路填充:把实际语料与平台 taxonomy 中预声明的概念集群清单比对,任何 < 2 篇的集群被点名为盲区,且引用指向 flag 出这个缺口 的论文(缺口本身也有证据支撑)。
- 来源质量 加权:meta-analysis 3×;peer-reviewed 顶刊 2×;working paper / pre-print 1× 但在引用 chip 上加
pre-print标。
T3 内部知识(「有多少篇?有 AER 文章吗?」)
覆盖: ~10% 的提问。用途: 回答 关于库本身 的元问题 —— 「我们收录了多少篇?」、「有 AER 的文章吗?」、「关于中国 ETS 有多少篇?」 等等。不走 LLM 生成。
实现: 答案查的是预先准备好的元数据表 library_meta_questions_v1.xlsx(由 curator 维护)。表里枚举了所有预期的元问题及其标准答案;系统把用户 prompt 匹配到最接近的表行。这样 T3 答案既确定性又快 —— 也避免 LLM 编造关于语料的数字。
页面功能:
- 直接元数据卡 —— 数字 / 清单直接从元数据表拿出来,没有 LLM 中介。
- 表版本 + 最近更新时间戳 让用户知道答案的鲜度。
- 「实时重算」按钮(仅管理员) —— 绕过表,直接从 Neo4j 现场重新统计(表过期时用)。
- 跳转到证据库 —— 对列表型元问题(例如 「哪些 AER 文章?」),跳进证据库并按对应子集筛好。
- 「这个问题不在表里」降级 —— 没有匹配的表行时,T3 降级到 T4(无法回答)并提示应把此元问题加入表。
- 同款可信度 + 反馈条 —— 因为答案是确定性的,可信度通常钉在 100%。
T4 外部知识 / 系统暂时无法回答的困难问题
覆盖: ~20% 的提问。当前状态: 这是系统 目前还 答不了的问题 —— 任何需要语料外知识、临时性事实、超出气候政策文献的具体地方政府查询、或者库未覆盖的相邻领域问题。spec 列举的例子:
- 「建筑领域有哪些气候政策?」 —— 邻接领域未覆盖。
- 「库里收录了多少篇?」 —— 若元问题在表里则由 T3 处理,否则落到 T4。
- 「中国出过哪些气候政策?」 —— 政府政策,不是文献。
- 「今天星期几?」 —— 临时性事实。
- 「某个论文未涵盖的具体气候政策被问到怎么办?」 —— 超出语料。
- 「重庆市面临的减排困境是什么?咋解决?哪个最有效?」 —— 多部分、超出语料、需要语料无法支撑的综合判断。
当前行为: chatbox 直接给出明确的 「暂时无法回答」 而不是编造。这是 设计上保守的拒答 —— 硬编码的哨兵响应,会解释为什么这个问题超出范围。长期: 团队希望随着语料扩张以及外部知识工具(实时网检、政府政策爬虫、实时事实查询)接入,把拒答率降下来。目前尚未解决。
页面功能:
- 「暂时无法回答」哨兵卡片 —— 标准拒答卡,说明触发了哪种原因(需要外部知识 / 超出语料 / 元问题尚未准备 / 邻接领域)。
- 原因分类器 —— 把拒答细分为:外部事实、地方政府、邻接领域文献、临时性查询、元数据未准备。
- 最近 in-corpus topic 建议 —— 点出与原问题最接近、库内有覆盖的题目,给一个「试试这个」chip 把改写后的 prompt 预填进去。
- 「提交以待将来覆盖」按钮 —— 把未答问题写入 triage log,团队据此决定是否扩库或加表。
- 临时性 banner —— 显式把这一档定性为 已知短板:外部知识接入在长期路线图上。
知识图谱可视化(/graph)
用途: KG 的力导向视图,用来在任意节点(Paper / Finding / Driver / Outcome / Concept)周围探索邻居。
页面功能:
- 力导向画布 基于
react-force-graph-2d—— 初始视图显示顶层集群。 - 节点类型筛选 chip —— 切换 Paper / Finding / Driver / Outcome / Concept 的可见性。
- 搜索栏 —— 节点名模糊匹配,选中后画布对中到该节点。
- 点击展开 —— 点节点展开 1-hop 邻居;双击展开 2-hop。
- 悬停预览 —— tooltip 显示节点标题、类型、论文数、最近更新日期。
- 「在图中查看」跳转 —— 平台任何位置的引用 chip 都可深链到这里并预选目标节点。
- 边类型图例 —— 关系类型说明(cause / mechanism / contradicts / cites / aggregates)。
- 缩放 / 平移 / 小地图 用于定位。
- 导出 PNG / SVG 用于幻灯片。
证据库(/evidence)
用途: 可浏览的语料索引。同一份底层数据的两种视图。
页面功能:
- 视图切换 —— Paper view(一行一篇论文)与 Finding view(一行一条 finding)切换。
- 筛选 chip —— 年份区间、期刊、国家、工具类目、方法(DiD / SC / CGE / 理论 / meta-analysis)、刊物层级(顶刊 / 其他 / pre-print)。
- 排序菜单 —— 相关度、引用数、发表年份、入库时间。
- 搜索栏 —— 在标题 + 摘要 + finding 文本上做全文检索。
- 批量选择 + 导出选中(BibTeX / CSV / Zotero)—— 把筛出的子集带出平台。
- 逐行「在图中查看」 跳转到知识图谱页。
- 顶部覆盖度指示 —— 复述 C5 元卡的数值(库内多少篇 / 盲区在哪)。
论文详情页(/papers/:id)
用途: 单篇论文的全部抽取信息。
页面功能:
- 元数据 header —— 标题、作者、期刊、年份、DOI、引用数、刊物层级徽章。
- Findings 列表 —— 每条抽取出的 finding 一张卡(claim、证据片段、方法标签、定量效果区间,如果有的话)。
- 「在图中查看」 跳转到以该论文节点为中心的图视图。
- 逐 finding 反馈 —— 👍 / 👎 反馈抽取质量(用于管理端 re-review 优先级)。
- 引用本文 —— 复制 BibTeX / RIS / Chicago / APA 引用片段。
- 打开原文 PDF —— 链接到来源(如有权限)或 open-access 版本。
- 相关论文条 —— KG 邻居论文(引用 / 被引 / 同方法)。
Finding 详情页(/findings/:id)
用途: 单条抽取 finding 的全部元数据。
页面功能:
- Claim 文本 —— 系统抽取出的结构化主张(主语 + 关系 + 客体 + 效果)。
- 证据片段 —— 源论文中支撑该主张的逐字片段,带位置 offset 以便审计。
- 来源论文上下文 —— 论文标题、所在章节、页码。
- 相关 findings —— 有类型关系(supports / contradicts / replicates / generalises)。
- LLM-judge 分数 —— 自动评测器在准确性 + 可追溯性 + 一致性三个维度的打分。
- 重新评测按钮(仅管理员) —— 用新版 prompt 重跑 LLM-judge。
- 「在图中查看」 跳转到以该 finding 节点为中心的图视图。
Topic / 分类树浏览器(/topics)
用途: 把平台 taxonomy(X → Y schema)以树视图的方式展开,比主页的卡片视图更适合系统性浏览。
页面功能:
- Driver 树 (左栏)—— 可折叠树:根类目 → 子类目 → 叶概念。
- Outcome 树 (右栏)—— 同结构。
- 每节点论文数 + 最近入库日期。
- 桥视图 —— 同时点击 Driver 叶与 Outcome 叶,显示交叉单元的证据数(例如 Acute Extreme Weather × Firm Entry-Exit = 4 篇)。
- Taxonomy 编辑按钮(管理员) —— 打开 curation 工作流(见 Admin 工具)。
数据入库(/ingest)
用途: 管理员把新论文加入语料库的入口。上传 PDF,系统自动跑 LLM 抽取 finding、构建证据索引、写入 Neo4j —— 一键走完全部流程。带去重检测,避免同一篇论文被重复入库。
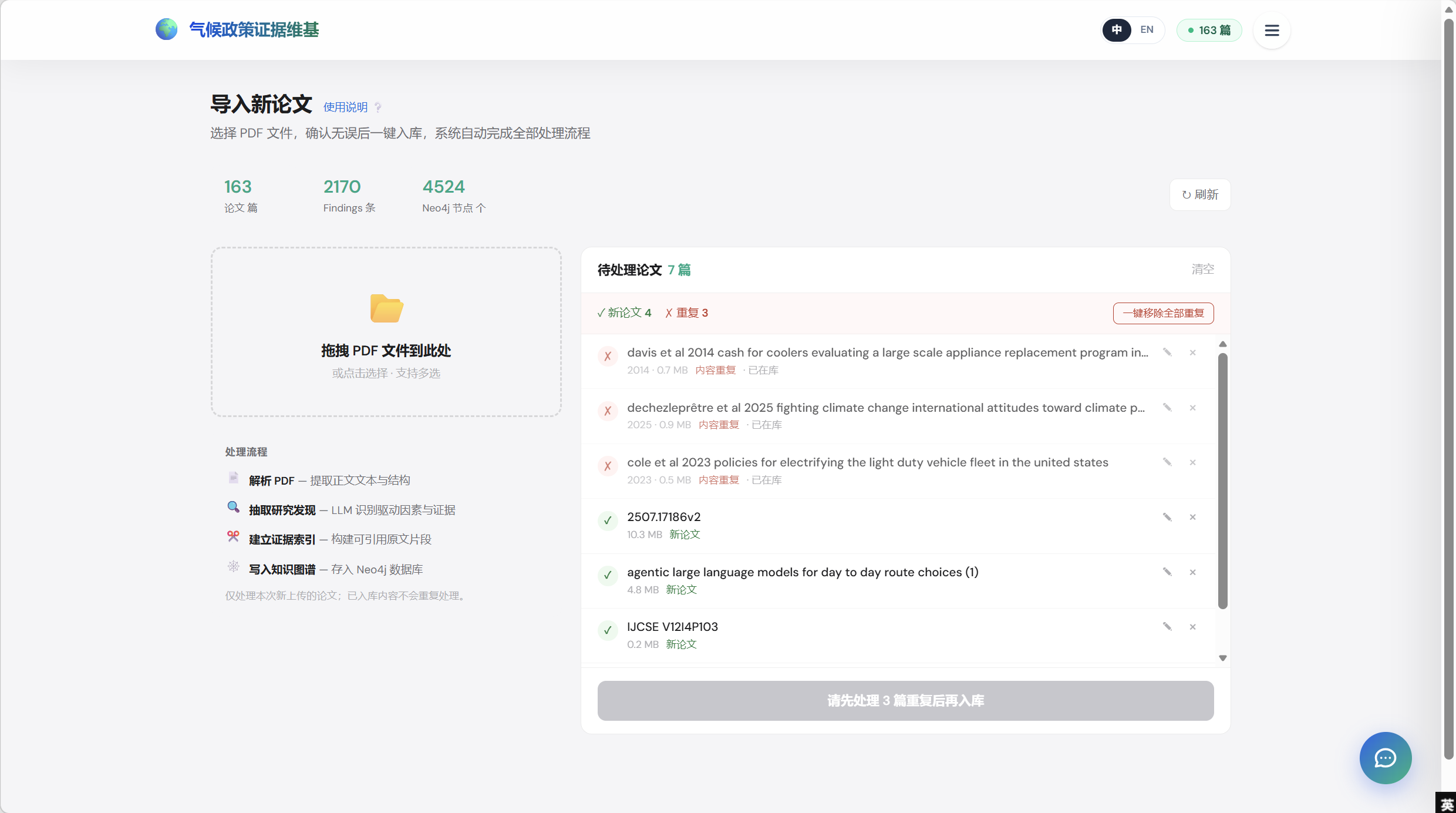
页面功能:
- 实时语料 KPI(顶部)—— 三个 tile 实时从 Neo4j 拉取:论文数、findings 数、KG 节点数(截图里 163 / 2170 / 4524)。带「刷新」按钮强制重读。
- 拖拽上传区域 —— 一次支持多个 PDF;也可点击打开文件选择器。
- 处理流程图例 —— 系统对每个新 PDF 跑的四步:① 解析 PDF、② LLM 抽取 finding、③ 构建证据索引、④ 写入 Neo4j。入库进行中时这一区图例还兼作进度 UI。
- 幂等性说明 —— 显式脚注「已入库内容不会重复处理」,是平台对用户的成本 / 时间保证。
- 待处理论文列表(右侧)—— 每个上传的文件一行,带状态(✓ 新论文 / ✕ 重复)、文件大小、徽章(新论文 / 内容重复 · 已在库)、编辑元数据的铅笔图标、以及移除 ✕ 按钮。
- 去重 banner —— 总数 + 一键「移除全部重复」按钮,点击会先弹确认对话框再从队列里剔除。
- 提交闸门 —— 底部「入库」CTA 在还有未处理重复时是禁用的,按钮 label 直接告诉用户先做什么(「请先处理 3 篇重复后再入库」)。
- 逐行元数据编辑器 —— 铅笔图标打开模态框,可以在入库前纠正标题 / DOI / 作者,避免一处元数据错就要重新上传。
反馈收集(每条回答下内嵌)
用途: 收集每条回答的反馈,喂给离线权重校准。
功能:
- 👍 / 👎 chip 对 出现在每条回答下方。
- 可选评论框 —— 用户选了任意一个 thumb 后弹出。
- 快照持久化 —— 反馈 + 当下 整张 可信度卡的状态写入 SQLite(
agent/data/feedback.db)。 - OLS 校准 job —— 周期性离线 job 用累计的 👍 / 👎 重新拟合评分函数权重。
- 特征权重热更新 —— 管理员可不重新部署直接推新权重。
设置与偏好(/settings)
用途: 每用户的偏好与账户。
页面功能:
- 语言切换 —— UI 语言(中 / EN),与语料语言独立。
- 主题切换 —— 浅色 / 深色 / 跟随系统。
- 会话保留 —— 设置本地存储保留窗口(默认 30 条对话)。
- 引用导出默认 —— BibTeX vs RIS vs Chicago。
- API key 管理 —— 给直接使用平台读 API 的用户。
- 登出 + 清除本地数据 (强制重新登录 + 抹掉会话历史)。
状态
进行中(研究助理岗位,2026.01 至今)。